
This method of load balancing expects new connections to issue a fresh DNS query each time. Thus, it is prudent to consider the caching behavior of the client devices, as well as any DNS servers between them and Amazon Route53.
By default, the Time To Live (TTL) of an A record in Amazon Route53 is 300 seconds (5 minutes). This means clients and intermediate DNS servers should remember the last response for 5 minutes before discarding it and retrieving the record again, thus allowing the routing policy to potentially hand out a different IP this time. This value can be lowered to as little as 0, which means no caching at all should occur.
Unfortunately, not all devices obey the TTL given out by the authoritative name servers. This is particularly true of intermediate DNS servers. Some ISPs and operating systems optimize by overwriting the TTL with one they feel is more appropriate. Check with the owner of your DNS resolvers to see if this is happening or set up your own inbound private resolvers with Amazon Route53.
The tradeoff to lowering the TTL to a very low value is that you will incur more chargeable queries for Amazon Route53. As an example, let’s consider an application with 1,000 devices that are online 24/7 and all query DNS as often as the TTL allows:
| TTL | Queries Per Device /mo | Total Queries / mo | Cost |
| 300 | 8,761 | 8.7 million | $4 |
| 1 | 2,628,288 | 2.6 billion | $726 |
Figure 6.19 – Comparison of Amazon Route53 query charges by TTL for 1,000 devices
AWS Local Zone as primary with parent region as secondary
When using an AWS Local Zone to reduce first-hop latency for users in a given metro area, using the parent region as a failover target is straightforward with AWS Route53. Separate ALBs, each with their own target groups, are created—one in the parent region and one in the AWS Local Zone:
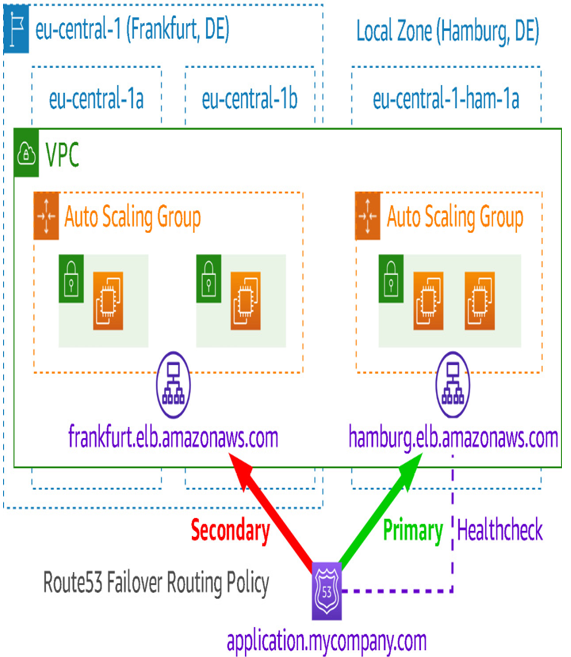
Figure 6.20 – Using Route53 to preferentially route traffic to the Hamburg zone
First, within a Route53 Hosted Zone for your public-facing DNS domain, create a health check that points to the preferred ALB.
Second, create two ALIAS records, one pointing to each ALB. Both records should have the same record name (i.e. myapp.mycompany.com). Use a failover routing policy with the record pointing to the preferred ALB set as primary and the other record set as secondary. When you create the primary record, attach the health check created earlier. See the following figure for an example of this configuration:

Figure 6.21 – Route53 Primary/Secondary failover example